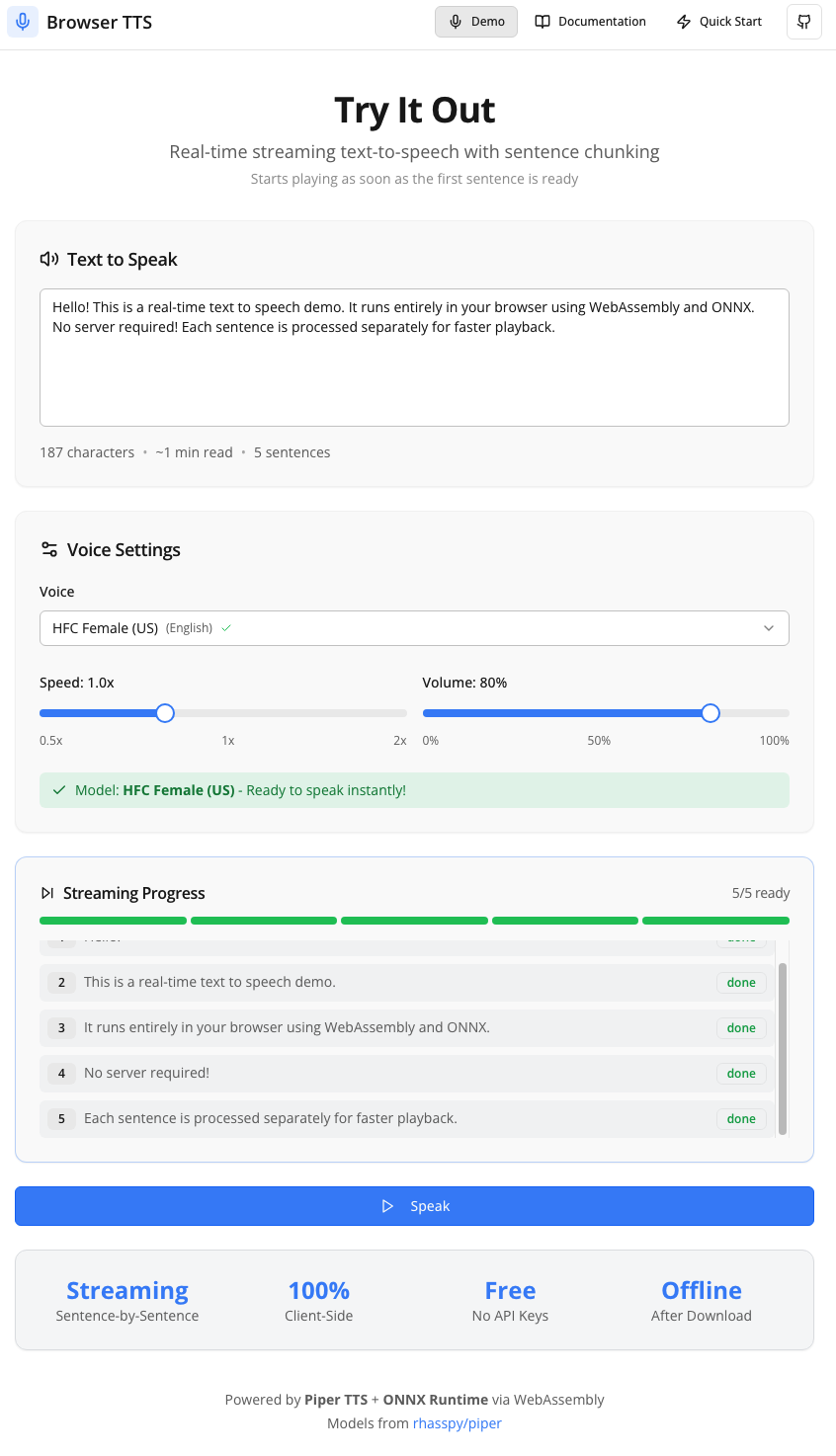
This project is a high-performance, browser-based text-to-speech system that runs entirely on the client. It utilizes VITS neural TTS models compiled to WebAssembly via ONNX Runtime, enabling streaming audio playback, multi-core parallel processing, and offline capability without server costs or API keys.
Features
100% client-side processing with no server dependencies
Streaming playback allowing audio to start before full generation
Multi-core WebAssembly threads for parallel sentence processing
Eight built-in natural voices across English, German, French, and Spanish
Offline support via browser IndexedDB caching of voice models
Privacy-first architecture ensuring no data leaves the local machine
Quickstart
git clone https://github.com/davidbmar/Browser-Text-to-Speech-TTS-Realtime.git
cd Browser-Text-to-Speech-TTS-Realtime
npm install
npm run dev
The application is built with React 18, TypeScript, and Vite. It leverages the @diffusionstudio/vits-web library for model inference. The UI is styled with Tailwind CSS and shadcn/ui components. State management for TTS operations is handled by a custom useTTS hook that interfaces with a TTSEngine class, which manages sentence splitting, chunk generation, and audio playback synchronization.
How it runs
sequenceDiagram
participant User
participant Component
participant Hook as useTTS
participant Engine as TTSEngine
participant WASM as WebAssembly
participant Audio as HTMLAudioElement
User->>Component: Click Speak
Component->>Hook: speak text
Hook->>Engine: process text
Engine->>Engine: split into sentences
loop For each sentence
Engine->>WASM: generate audio chunk
WASM-->>Engine: return audio blob
Engine->>Audio: play chunk
Audio-->>User: output sound
end
Engine-->>Hook: update progress
Hook-->>Component: update state
Component-->>User: render progress
How to apply & reuse
Integrate the useTTS hook into any React component to add voice capabilities. Configure voice ID, speed, and volume via hook options. Use the returned speak, stop, pause, and resume methods to control playback. Monitor state variables like isReady, isPlaying, and progress to update UI elements dynamically.
At a glance
CapabilitiesReal-time neural speech synthesisParallel multi-core processingStreaming audio playbackOffline model cachingVoice selection and configurationPlayback control pause resume stop